Introduction
Here's a quote from the abstract of the paper A Neural Algorithm of Artistic Style by Gatys et al.
The idea presented by the above paper, is an artificial system based on a Deep Neural Network that does just that. It separates and then recombines the content and style of two arbitrary images, creating a whole brand new work of art!In fine art, especially painting, humans have mastered the skill to create unique visual experiences through composing a complex interplay between the content and style of an image.
Algorithm
The main idea of the algorithm is actually quite simple! Let's image that we have two different baselines: a content representation of our goal, and a style representation of our goal. Given these two, our algorithm just continues to alter the pixel values of our image while minimizing the loss according to the baseline content representation and the loss according to the basline style representation. In order to actually accomplish this, we need to find a way to get a baseline first!
Content and Style Representations
Here we utilize the idea that when Convolutional Neural Networks are trained on object recognition, they develop a very good representation of the image. By leveraging a CNN that has been trained on a large image set, we can feed in a content and style image and extract features along the way that give us the content and style representations we are looking for!

Higher layers in the network capture the high-level content in terms of objects and their arrangement in the input image but do not constrain the exact pixel values of the reconstruction. We therefore refer to the feature responses in higher layers of the network as the content representation. To obtain a representation of the style of an input image, we use a feature space that consists of the correlations between the different filter responses over the spatial extent of the feature maps. By including the feature correlations of multiple layers, we obtain a stationary, multi-scale representation of the input image, which captures its texture information but not the global arrangement. We refer to this multi-scale representation as style representation.
Model Architecture
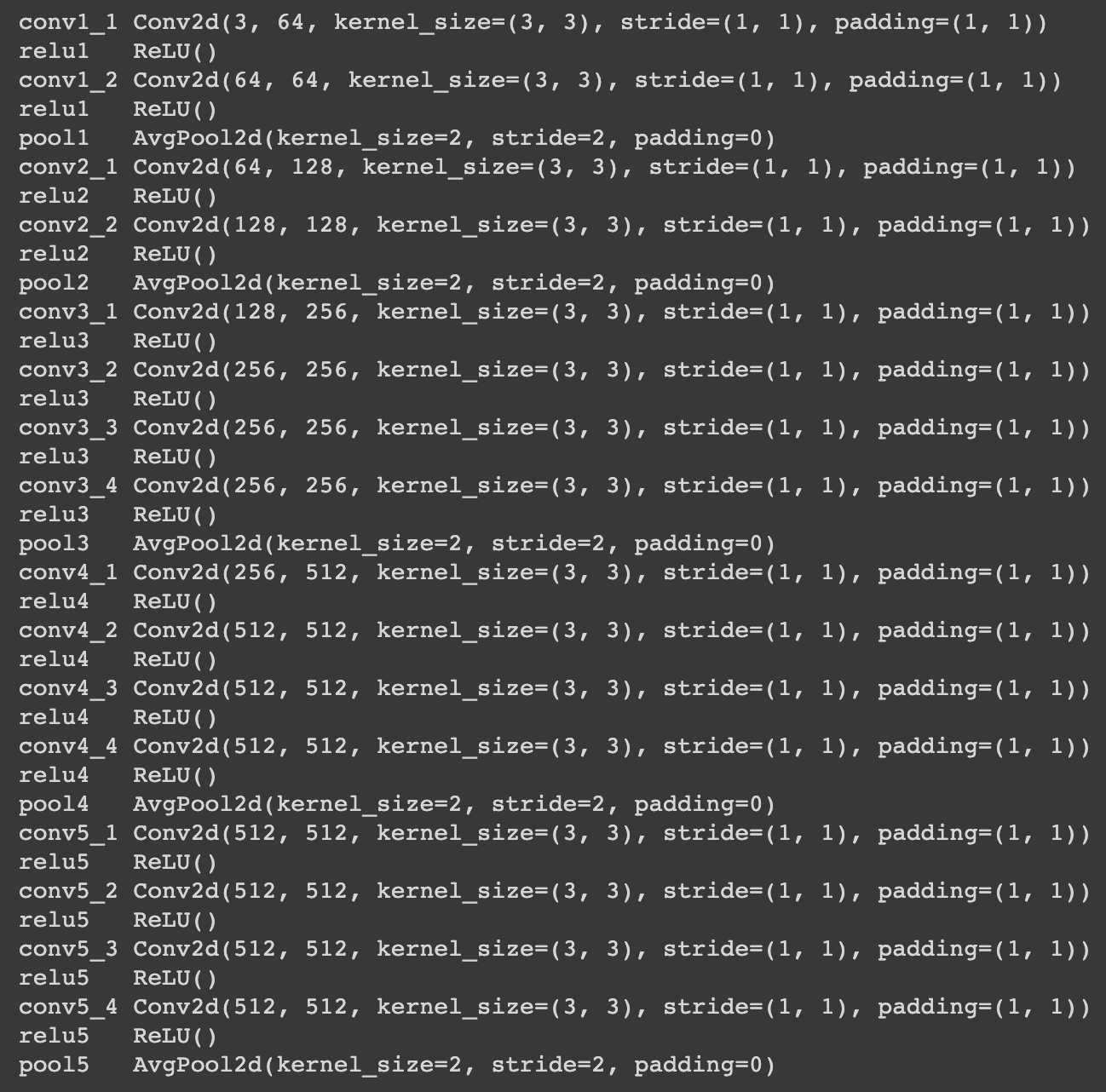
As suggested in the paper, we use a pretrained VGG-19 network with average pooling instead of max pooling and without any of the fully connected layers for the CNN referred to above. The architecure can be seen below.
Loss Functions
Now we are in dire need of a way to quantify the losses we mentioned earlier. As definied in the paper, we have the following equation for content loss:
$$\mathcal{L}_{content}(\vec{p}, \vec{x}, l) = \frac{1}{2} \sum_{i, j}(F^{l}_{ij} - P^{l}_{ij})^{2}$$
where we let \(\vec{p}\) and \(\vec{x}\) be the original image and the image that is being generated and \(P^{l}\) and \(F^{l}\) be their feature representations extracted from layer \(l\) from the model. Now, for style loss, we have a few more moving parts. First we need the measure of the correlations between the different filter responses which is given by the Gram matrix \(G^l\in\mathbb{R}^{N_l\times N_l}\) such that
$$G_{ij}^{l} = \sum_{k}F_{ik}^{l} F_{jk}^l.$$
Now we let \(\vec{a}\) and \(\vec{x}\) be the original image and the image that is being generated and \(A^{l}\) and \(G^{l}\) be
their style representations extracted from layer \(l\) from the model. We now have the following:
$$E_{l} = \frac{1}{4 N_{l}^2 M_{l}^2} \sum_{ij}(G_{ij}^{l} - A_{ij}^l)^{2}$$
$$\mathcal{L}_{style}(\vec{a}, \vec{x}) = \sum_{l=0}^{L} w_{l} E_{l}.$$
Given these equations, we then define a total loss function,
$$\mathcal{L}_{total}(\vec{p}, \vec{a}, \vec{x}) = \alpha \mathcal{L}_{content}(\vec{p}, \vec{x}) +
\beta\mathcal{L}_{style}(\vec{a}, \vec{x})$$
where \(\alpha\) and \(\beta\) are the weighting factors for content and style reconstruction respectively. We matched the content representation on layer conv4_1, and the
style representations on layers conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1 (\(w_l =
1/5\) in those layers, \(w_l = 0\) in all other layers) .
Training
Now we can just use gradient descent to minimize the above loss function and find the optimal pixel values for our generated image. We used the L-BFGS algorithm for our optimizer and trained for \(500\) epochs. We left the \(\alpha=1\) and changed \(\beta\) accordingly to gain more or less of weight on the style loss.
Results
Neckarfront







Yosemite




Avenue of the Giants



Campanile


Failure



I suspect this case fails because there aren't very many distinguishable features in the image like nice strong edges, and thus the entire background of the mountainside becomes one incomprehensible wave of white, and the trees are the only things that end up looking like waves.